开源数据

ARIO
arXiv
·
20 Aug 2024
·
arXiv:2408.10899
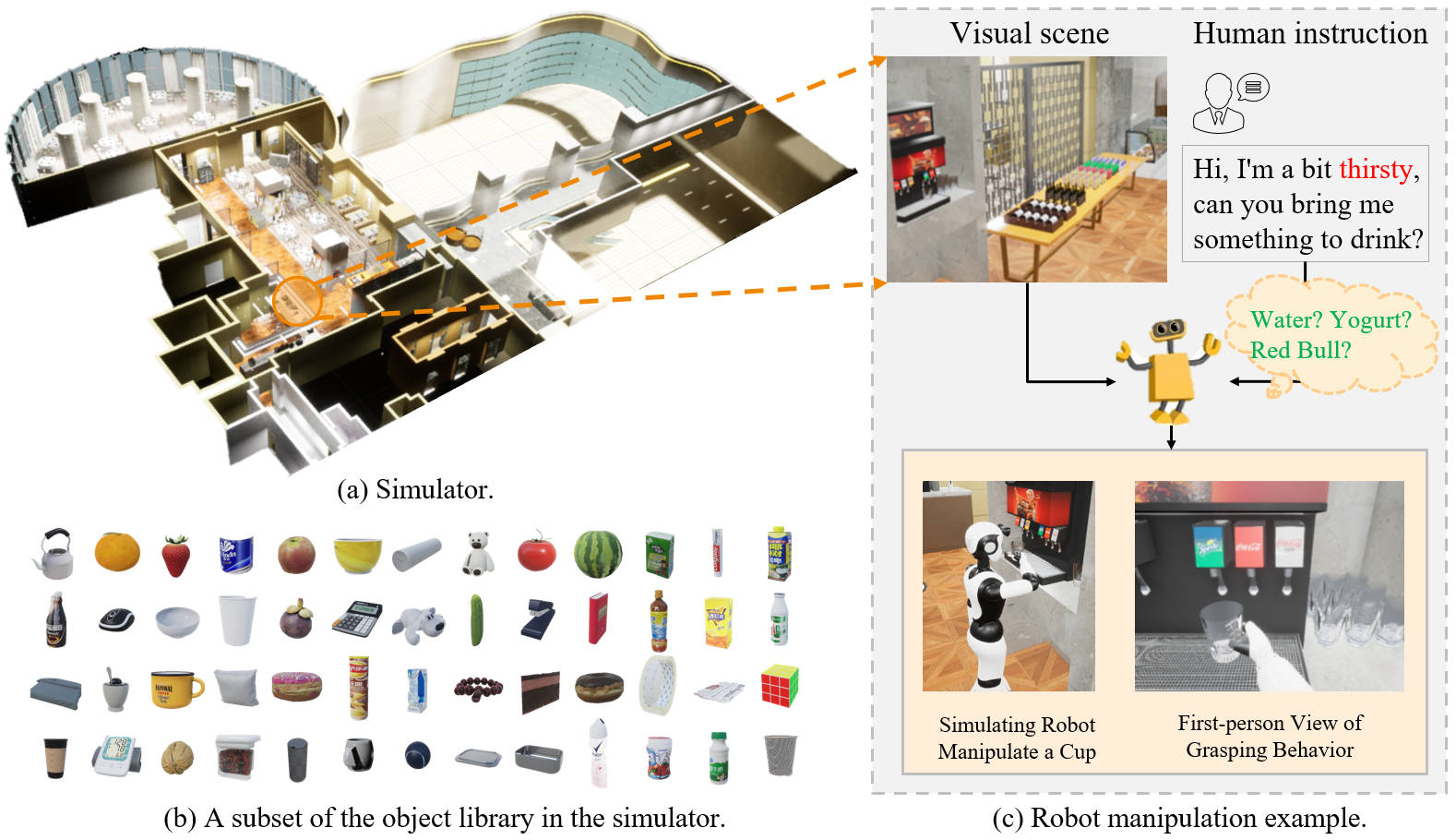
Embodied AI is transforming how AI systems interact with the physical world, yet existing datasets are inadequate for developing versatile, general-purpose agents. These limitations include a lack of standardized formats, insufficient data diversity, and inadequate data volume. To address these issues, we introduce ARIO (All Robots In One), a new data standard that enhances existing datasets by offering a unified data format, comprehensive sensory modalities, and a combination of real-world and simulated data. ARIO aims to improve the training of embodied AI agents, increasing their robustness and adaptability across various tasks and environments. Building upon the proposed new standard, we present a large-scale unified ARIO dataset, comprising approximately 3 million episodes collected from 258 series and 321,064 tasks. The ARIO standard and dataset represent a significant step towards bridging the gaps of existing data resources. By providing a cohesive framework for data collection and representation, ARIO paves the way for the development of more powerful and versatile embodied AI agents, capable of navigating and interacting with the physical world in increasingly complex and diverse ways.
开源项目的代码

TIP-Editor
[no publisher info]
·
[no date info]
·
[no id info]
TIP-Editor is a 3D scene editing framework that combines text, image prompts, and a 3D bounding box to enable accurate control over the appearance and placement of the edited content, utilizing a stepwise 2D personalization strategy and 3D Gaussian splatting for precise local editing.

To Err like Human
[no publisher info]
·
[no date info]
·
[no id info]
This repository contains the implementation of our paper “To Err like Human: Affective Bias-Inspired Measures for Visual Emotion Recognition Evaluation”, which introduces a new evaluation metric for Visual Emotion Recognition (VER).
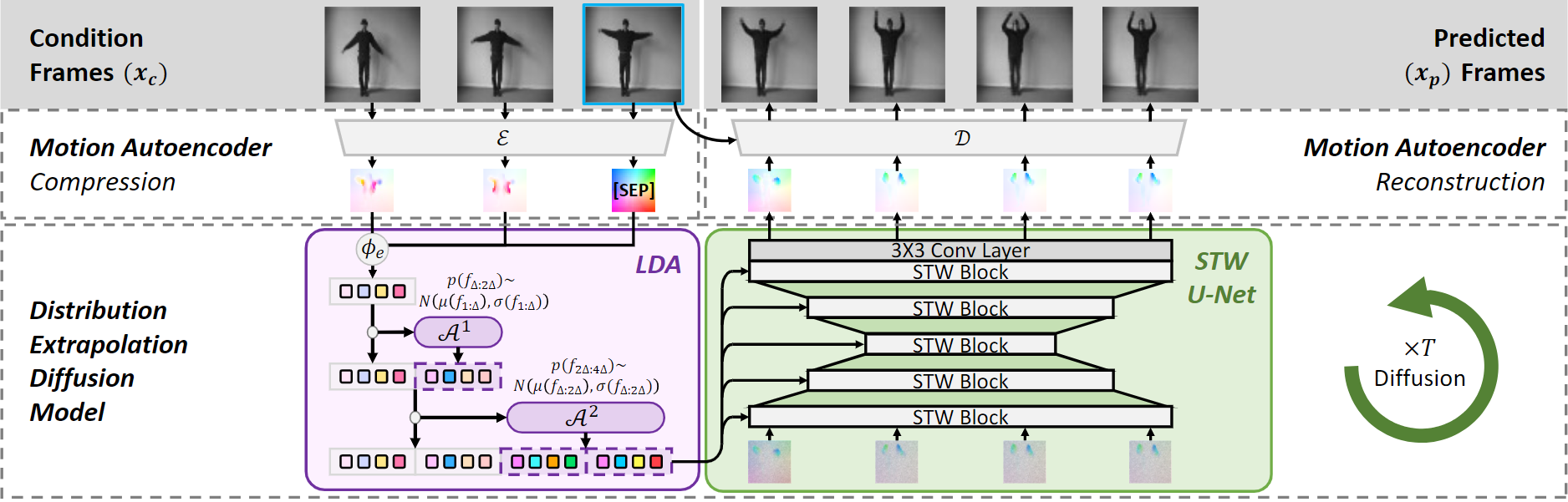
ExtDM
[no publisher info]
·
[no date info]
·
[no id info]
We present ExtDM, a new diffusion model that extrapolates video content from current frames by accurately modeling distribution shifts towards future frames.

CatVTON
[no publisher info]
·
[no date info]
·
[no id info]
CatVTON is a simple and efficient virtual try-on diffusion model with 1) Lightweight Network (899.06M parameters totally), 2) Parameter-Efficient Training (49.57M parameters trainable) and 3) Simplified Inference (< 8G VRAM for 1024X768 resolution).

HCP-Diffusion
[no publisher info]
·
[no date info]
·
[no id info]
HCP-Diffusion is a toolbox for Stable Diffusion models based on Diffusers. It facilitates flexiable configurations and component support for training, in comparison with webui and sd-scripts.
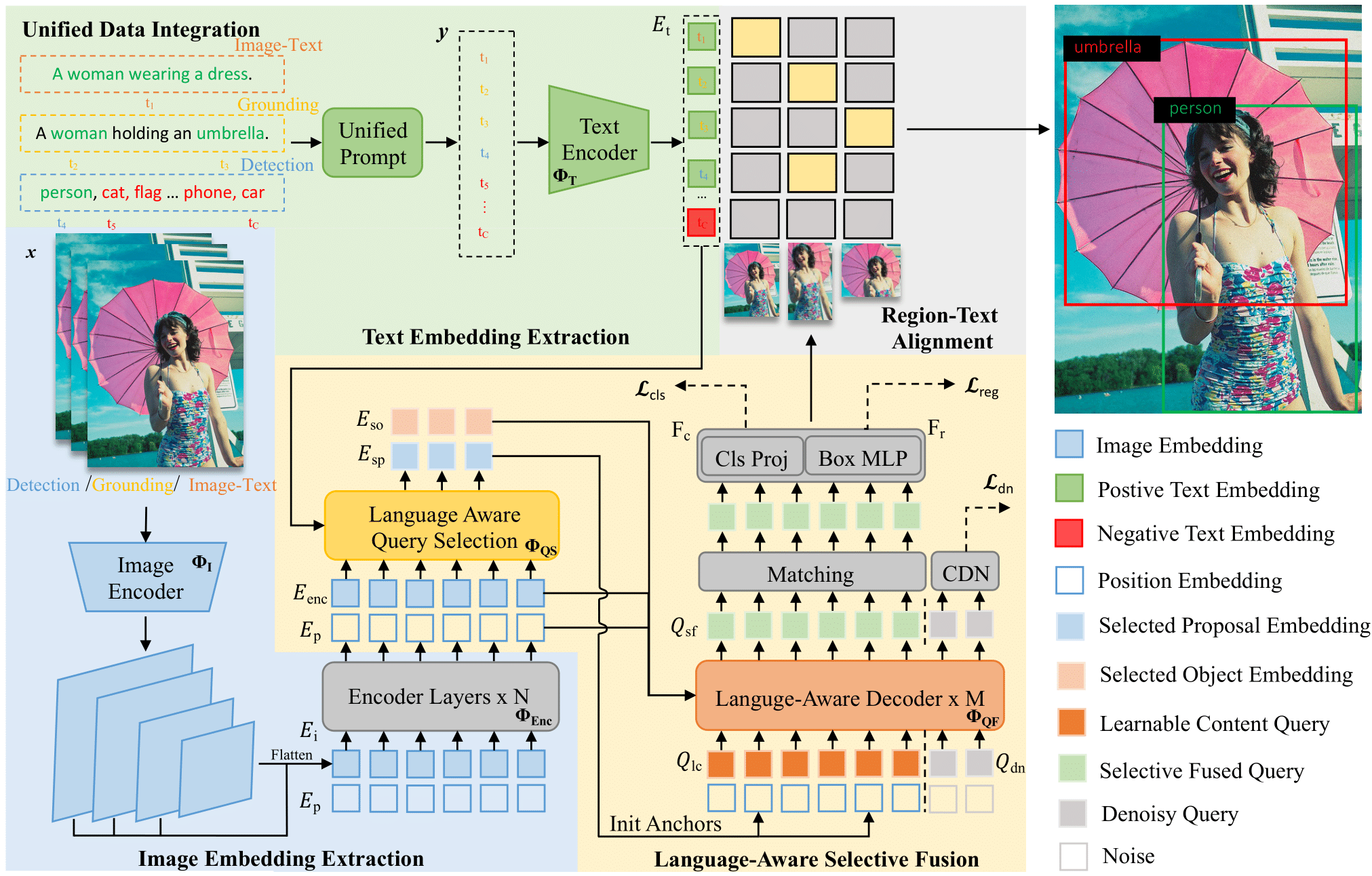
OV-DINO
[no publisher info]
·
[no date info]
·
[no id info]
This project contains the official PyTorch implementation, pre-trained models, fine-tuning code, and inference demo for OV-DINO.

REVERIE
[no publisher info]
·
[no date info]
·
[no id info]
A large-scale dataset with rationale annotations to enhance model reasoning by predicting justifications for correct or incorrect responses.
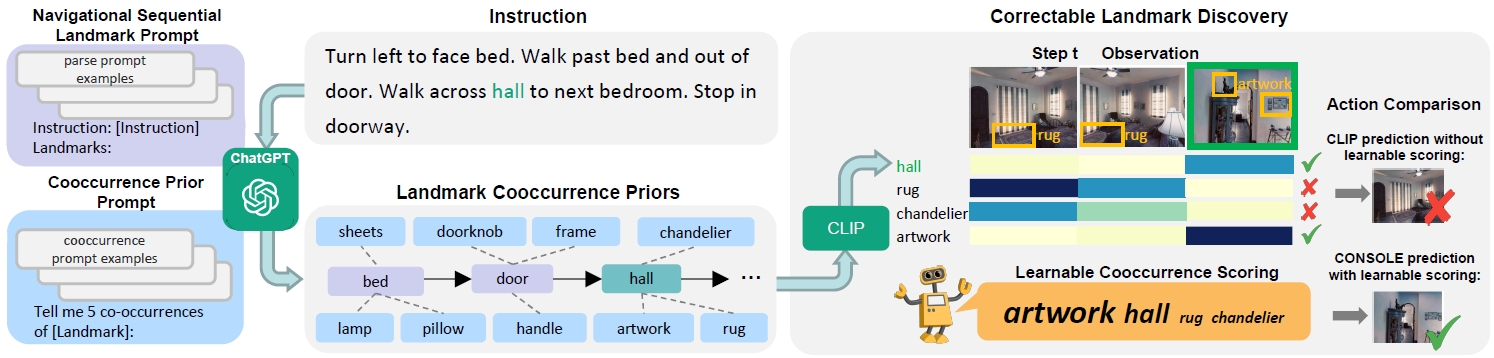
CONSOLE
[no publisher info]
·
[no date info]
·
[no id info]
A new Vision-Language Navigation paradigm that uses ChatGPT and CLIP for open-world landmark discovery, correcting prior knowledge with a learnable co-occurrence scoring module to enhance navigation accuracy and outperform existing methods on benchmarks like R2R and R4R.
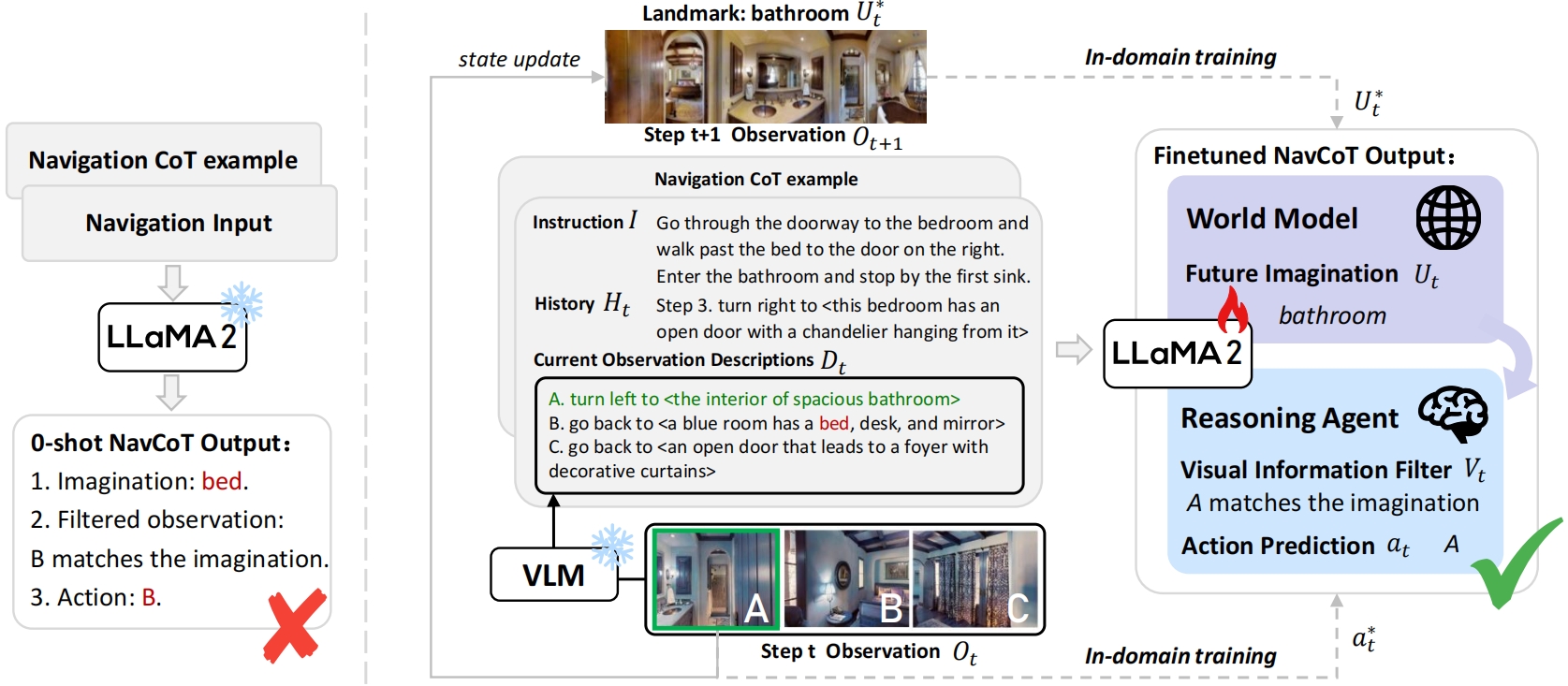
NavCoT
[no publisher info]
·
[no date info]
·
[no id info]
A parameter-efficient in-domain training strategy that enables large language models to guide navigational decision-making in Vision-and-Language Navigation tasks
Surfer
[no publisher info]
·
[no date info]
·
[no id info]
A robot manipulation framework that improves natural language instruction understanding and physical action execution by explicitly modeling action and scene predictions in a multi-modal world model

DreamEditor
[no publisher info]
·
[no date info]
·
[no id info]
DreamEditor is a novel framework that enables controlled editing of neural fields using text prompts, allowing localized edits in specific regions of real-world scenes while maintaining consistency and generating realistic textures and geometry.

Fashion Matrix
[no publisher info]
·
[no date info]
·
[no id info]
Fashion Matrix is dedicated to bridging various visual and language models and continuously refining its capabilities as a comprehensive fashion AI assistant.
–>